Did you copy and paste this from the email you sent to Eli Sanders?
This is great Science. Have you checked out fivethirtyeight.com yet? Election data porn for DAYS...complete with charts! Would love to hear your thoughts on its methodologies
What's with you and the Central Limit Theorem? You don't need the CLT (or independence) to combine samples to obtain a better point estimate; you DO need to _account_ for non-independence when estimating the variance of the combined samples (and hence for constructing confidence intervals). Also be careful about giving a Bayesian interpretation to a frequentist construct. Thanks for the PSM.
umvue--
Fair enough. I'm always trying to balance how much detail I put into a slog post. CLT seems relatively accessible, compared to say the math estimate the variance of combined samples or a t-test.
I'm tempted to snip it out of the post now, but I think I'll let it stand, just with the note here that the central limit theorem is not required, nor is independence, to get some value from combining measures together.
What is your opinion of the Intrade-based sites? I'm rapidly cooling on them.
Never thought I'd live to see a live scientist endorse the "statistical tie" nonsense.
I thought that was for English majors.
Thanks for this post.
I like the analysis often done by Goldy of HorsesAss, where he simulates 1 million elections and creates a probability distribution of the outcome, like this:
http://www.horsesass.org/wp-content/uploads/wagov11jun08-400x300.png
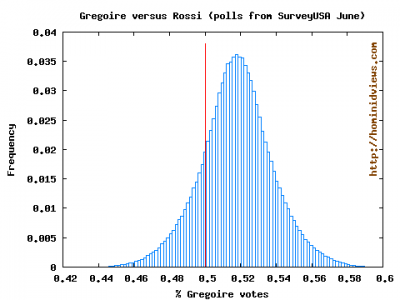
I simulated a million gubernatorial elections of 637 voters each election. Each voter in each election had a 50.4% chance of voting for Gregoire, a 46.9% chance of voting for Rossi, and a 3.5% chance of voting for neither.Gregoire won 824,097 of the elections, and Rossi took 9,687. In other words, the poll results suggest that, for an election held now, Gregoire would have an 83.2% probability of winning the election and Rossi would have a 16.8% chance of winning the election.
I don't know exactly how sound his methodology is, but what seems to be a narrow lead results in a high probability of a win.
w7ngman--
Statistical resampling is what I think Goldy used to generate that graph. It's a better way to confirm guesses about the variance of the data than the actual population percentage. In other words, it works better if you're trying to figure out if your estimated error margin is the actual error margin rather than who will win in November.
It's so far away from the election, almost any poll should be taken with a huge grain of salt. A good time to think about how you'll read the polls as we approach the election, to stop from biasing yourself.
sherman --
I've never seen fivethirtyeight.com before. Thanks for pointing it out.
On a very quick, cursory glance, it also seems to call states to easily. I want more toss-ups where the ranges overlap!
What Goldy did is definitely not resampling. He'd need access to at least all of the original polling responses to do any kind of resampling.
And what he did do is invalid.
First, 50.4 + 46.9 + 3.5 = 100.8 so he isn't even using legit probabilities.
Second, even if he repaired his probabilities, he's still assuming the sample means are the true population parameters. If he instead---going Bayesian---sampled probabilities from some assumed distribution (using the sample means and margins of error as parameters for that distribution), then ran his simulation using those sampled probabilities, then he'd see that the winner of the election isn't reliably predictable.
Jonathan, this is mf gorgeous. As you know. Thank you for helping the paper in this direction. You must be a complete insomniac.
On Slog, we currently cannot discuss travel, languages, history, geography, the New Yorker, or books, even when spiced, but we can discuss science facts because of Jonathan Golob. Science facts might be the most important of the above.
@6: Goldy posts this, but Darryl from hominidviews.com is the one that does the analysis. It isn't completely foolproof, partly for reasons already mentioned, and partly because it assumes that the errors given for the results are normal, uncorrelated, and the only source of error in the system.
no, dude, you need more than a cursory glance at fivethirtyeight.com. 538 uses detailed methodology to apply trends across congressional districts with similar demographics. The guy who runs it is the same genius who created PECTOA for the Baseball Prospectus.
Trust me, electoral-vote.com is so 2004. This years it's all about Nate at 538.
When are pollsters going to change their methodology to include people who don't have landlines, but only cell phones? I don't have any real suggestions for making this happen, but throw enough eggheads at it and something will change. I mention this because neither I nor most of my friends have a landline. I don't know what percentage of the population has ditched their landlines in favor of cells, or how polls are skewed because of that, but you'd think somebody would be working on adapting to 21st century technology already. (As we know, they didn't stop polling people via telegram until the mid-90's.)
538 is the real deal.
Nate Silver is the brains behind it and the guy is a math wizard - he's a legend in baseball circles for being by far the most accurate at ball player projections (PECOTA)
You need to read a his FAQ - much of the stuff is over the head of anyone without a PHD in statistics but it is grounded in hard science. He was recently hired by Rasmussen and appeared on CNN - FWIW the 'main stream' is taking him very seriously.
JG --
With the the understanding that sampling is not my bag (MCMC BMA and regression w/ maxent models is for now) and I'm a pedantic ass...
My understanding of one of the points of your post was that combining samples leads to better estimates so long as the samples are independent. This is absolutely true. My point is that this is true independent of the truth of the CLT. It's also true if the samples are not independent - you just need to account for the correlation. With surveys we're generally dealing with binomial random variables and all the mathematics of combining samples, even if correlated, is relatively simple and known. Historically, we've relied on the normal approximation (ah, CLT) to the binomial (see the quincunx for a pretty demo) since the calculations become intractable (the binomial formula contains a factorial). With computers we can do the exact calculations, however. Whatever, the normal approximation is good enough.
I've not spent too much time considering the Intrade-based sites. I do believe in the wisdom of crowds but... I also believe in their ignorance. I think the Intrade sample provides a great estimate of what the population believes about the future. I don't believe the Intrade sample provides a great prediction of what will happen in the future.
Most good pollsters use weighting to take cell phone-only households into account. Is it perfect, of course not. But people keep bringing this issue up as if they've made some great discovery that pollsters are too dumb to acknowledge. Maybe it was a big problem for polls five years ago, but nowadays it's taken into account.
Keep in mind that almost all good polls already weight for one or more factors (age, income, race, etc).
If you want solid info on polling you should check out http://www.pollster.com/blogs/ , one of the best around
Running a simulation ala Goldy (as described above) is a very simple matter and is "valid" conditional on the initial parameters being "valid". His probabilities should sum to one but that is not necessarily a deal breaker for the simulation. I'm guessing he got his numbers from some poll. Conditional on those numbers representing something about the voting population of the state of Washington he gets a point estimate of the probability of Gregoire winning the election. Fair enough. He should take it a step further and calculate the Monte Carlo error to put a confidence interval around that point estimate.
umvue I think it's your last point that makes me ultimately say his simulations are invalid---though unreliable is probably a better characterization. He could put a crude credible interval around his estimate just by eyeballing the posted histogram. But that wouldn't include any error propagated through from the substitution of (known to be uncertain) sample means for population parameters.
Since his simulation basically says "Let's assume the poll's estimates are the true values...", I was calling it invalid because I rejected that assumption.
And also... the mean of his simulated distribution seems to disagree with the expected value according to his parameters---and the histogram looks smooth enough that it's probably not a simulation size issue. So there might be other reasons it's unreliable as well.
Another good rule of tumb is to report on the same polls consistently, better yet, averages of the same polls, rather than searching out for the single poll of the day that supports your cause and picking and choosing at random as was done today in reporting the Quinnipiac poll.
That's not just wrong, it's dishonest, in the way that Pres. Bush cherrypicked intel.
@19
PC, shouldn't you preface your posts by pointing out that your predictions as to who would be the Democratic nominee were wrong every step of the way? Honestly, shouldn't you warn everyone not to trust someone who is batting a zero?
Danny --
Don't want to be in the position of defending Goldy since I've no idea what the hell he's doing. Monte Carlo methods are one (frequentist) way to account for the variability and I agree that he's probably not accounting for all of it. As for his histogram, I suspect what's going on is a function of the supposed 3.5% of poll respondents who will not vote for either candidate.
Oh yeah, I'm a big fan of using Monte Carlo methods to explore estimator variance, but in this specific model I think it's both unnecessary and won't capture the uncertainty we really care about. If he takes the variance of one of his simulated vote proportions he'll no doubt find it's p(1-p)---which could have been analytically derived ahead of time.
But that doesn't say anything about the uncertainty in p, which I think he's claiming to get around.
At any rate, it's still great that people care enough to try their own simulations and get into statistics as a hobby. Maybe everyone will gradually become more statistically literate and we'll regain some 18th century golden age when any educated person could call herself a scientist...
I'm an electrical engineer, and have spent more than my share of time poring over numbers, noise analyses, and error budgets. So, I believe I can say with some authority that you are a bunch of nerds.
Polls of polls rule.
And are totally useless.
and, technically, what you need is a true random sample of actual voters - most polls are polls of highly likely voters who have landlines and answer phone polls.
Comments Closed
Comments are closed on this post.
{kind=link}